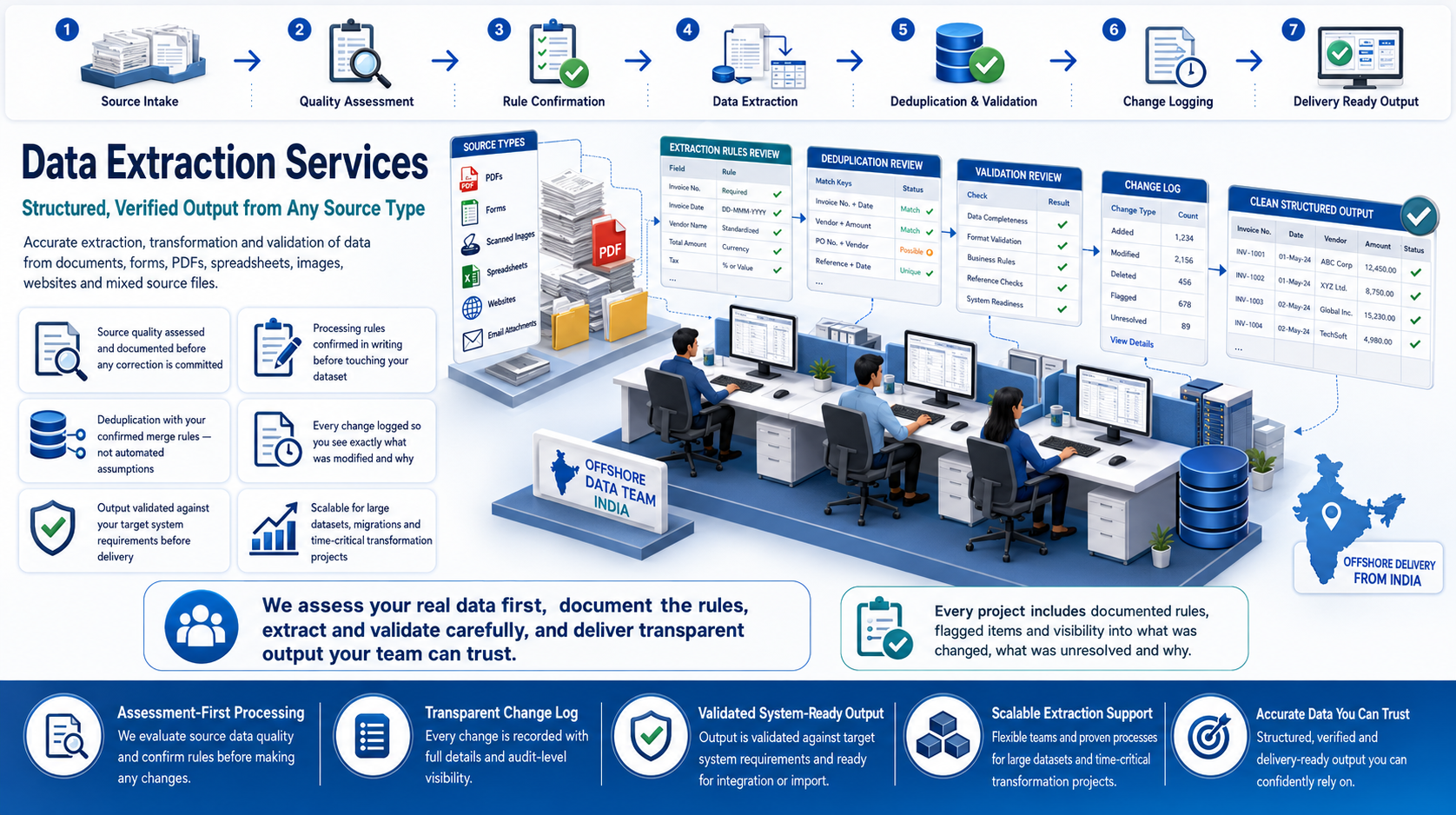
Effective data extraction requires understanding the source structure before building the extraction workflow. Which fields are consistently present? Which vary in position across documents? Which require contextual interpretation to extract correctly? Which are sometimes absent and need to be flagged rather than filled with placeholder values? These questions are answered in the source analysis before any extraction work begins.
For document-based extraction, we work with PDFs (native text and scanned), Word files, Excel files, scanned images, printed reports and legacy electronic files. For web-based extraction, we collect from websites, portals, directories and public databases with systematic source coverage and quality checking throughout.
Our India-based extraction team provides reliable, scalable extraction capacity for one-time projects and ongoing recurring collection workflows — at rates that make offshore extraction practical for projects that would be too expensive or too slow to handle with in-house resources.