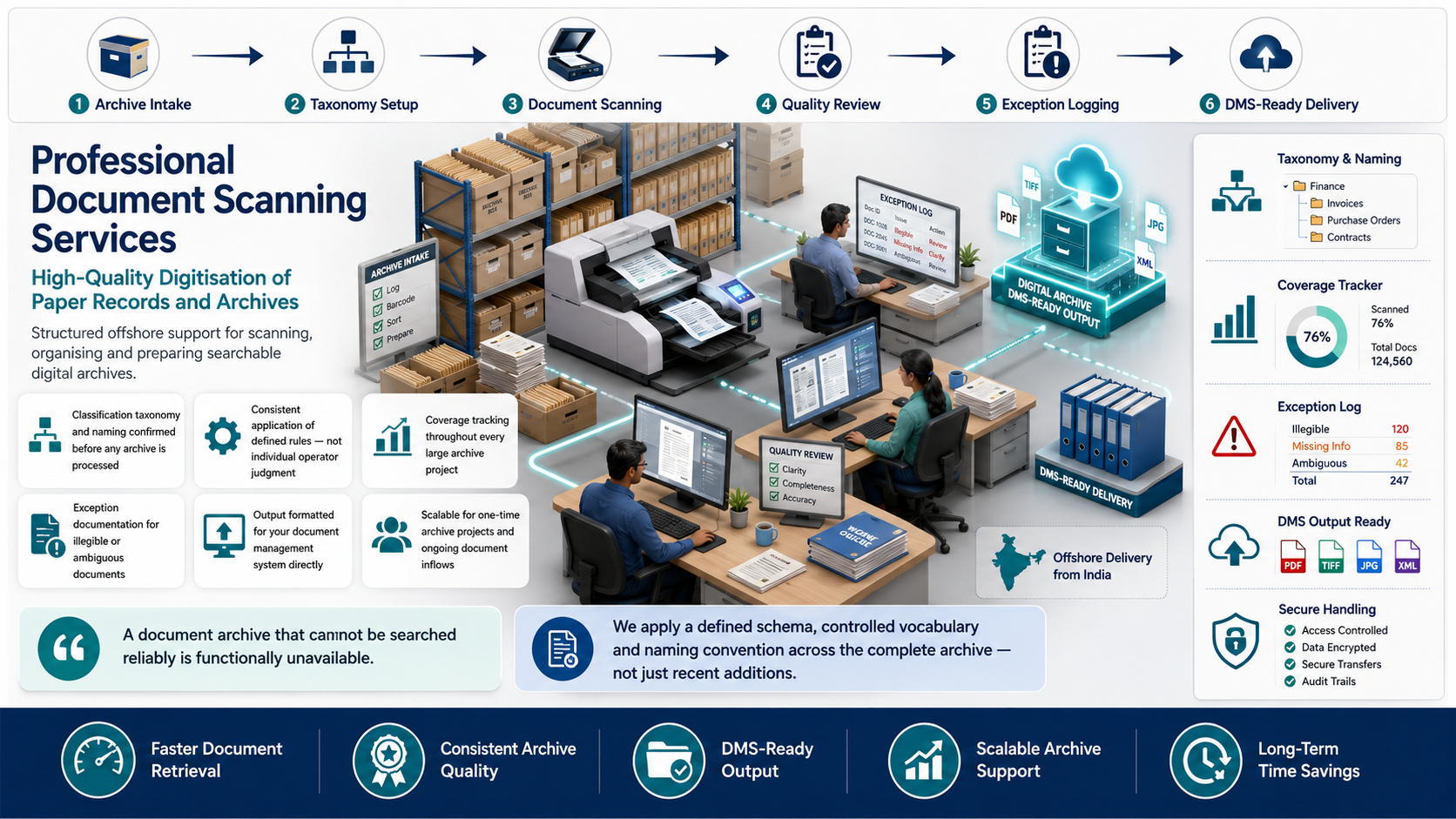
The gap between a scanned document collection and a functional digital archive is significant. A pile of scanned images with sequential file names does not allow retrieval by document type, date, client or subject. Adding OCR without manual correction produces searchable text that misidentifies characters and produces false negatives in search results. Naming and classifying documents systematically — the work that makes them retrievable — requires the same systematic effort whether the document count is 1,000 or 100,000.
We plan the scanning and digitisation workflow around your document types, retention requirements, target archive platform and primary retrieval use cases. Naming conventions, folder hierarchy, metadata fields, OCR accuracy standards and archive platform compatibility are all confirmed before the first document is scanned.
As a professional document scanning outsourcing partner, SDES coordinates the complete digitisation process — from scanning logistics through image processing, naming, classification and archive delivery — giving you a fully functional digital archive rather than just a folder of image files.