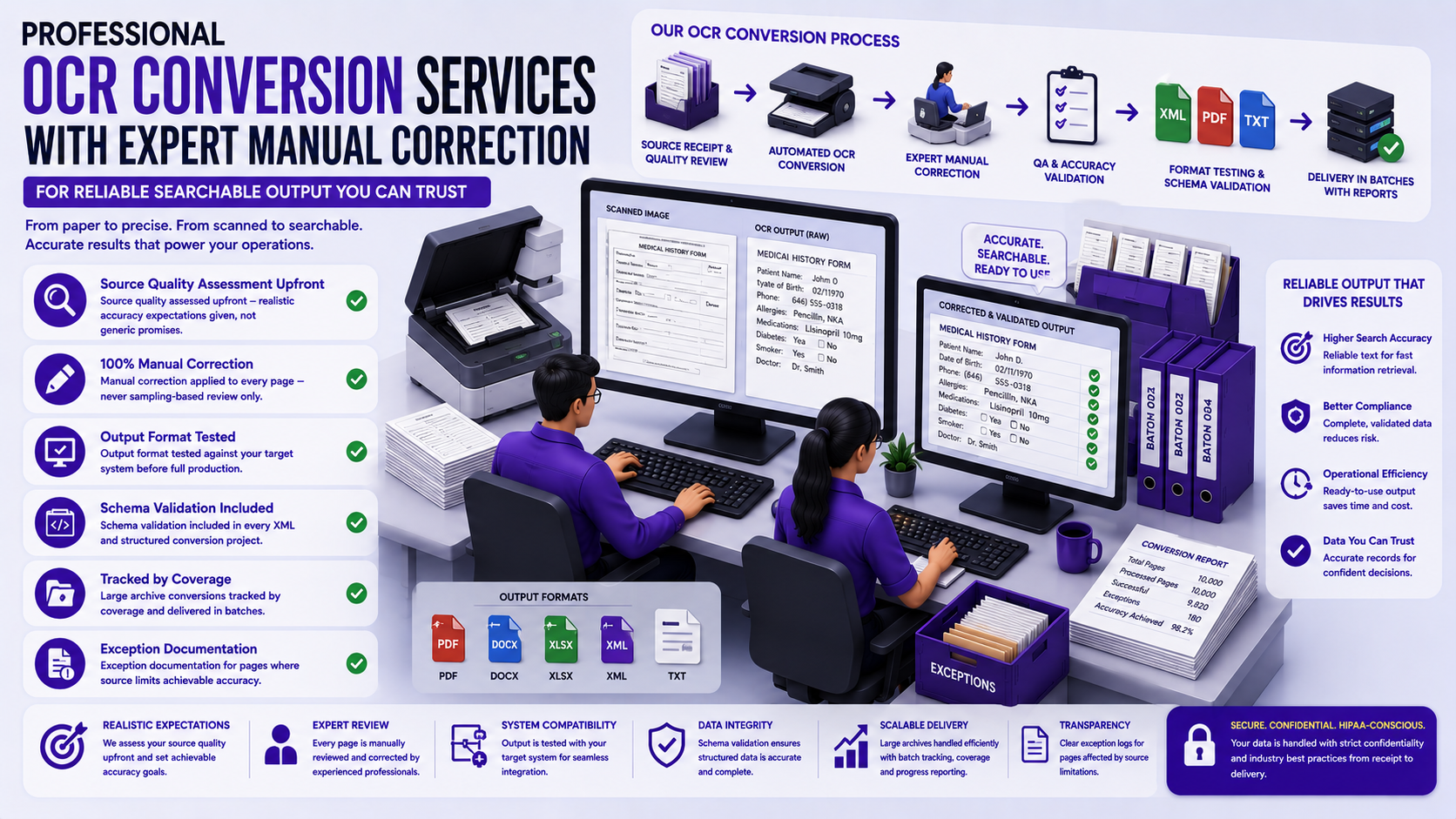
OCR accuracy is primarily determined by source quality and document characteristics — scanning resolution, font clarity, layout complexity and physical document condition. Good source material at adequate resolution with clear, standard fonts achieves high initial OCR accuracy. Degraded, complex or non-standard sources require proportionally more manual correction effort.
We always combine OCR processing with manual correction — never treating automated output as a completed deliverable. The correction process is systematic, not sampling-based: every page of output is reviewed against the source for character errors, structural problems and formatting failures.
As a professional OCR conversion outsourcing company in India, SDES provides cost-effective, high-volume OCR processing and correction capacity that makes systematic, accurate OCR conversion affordable for archive projects where doing the job correctly matters.